 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask the Target: A Plug-and-Play Regularizer Against LoRA Forgetting
May 28, 2026Low-Rank Adaptation (LoRA) has become one of the most widely used fine-tuning mechanisms for adapting large language models to new domains, tasks, and users. Yet adaptation performance alone can obscure an important failure mode: LoRA updates may improve performance on the target distribution while degrading prior capabilities learned during pretraining and alignment. We show that this forgetting becomes especially severe when the adaptation distribution differs substantially from the models original training or alignment distributions. The challenge is amplified in practical settings, where the original training and alignment data are typically unavailable. Motivated by this constraint, we study how LoRA based adaptation balances new learning against forgetting in a replay-free setting, and introduce a simple output space regularizer that can be added directly to existing training pipelines. Our method removes the ground-truth token from both the base and adapted model distributions, renormalizes the remaining probabilities, and applies KL regularization only over the non-target vocabulary. This preserves the base models relative preferences among alternative tokens without directly opposing the cross-entropy signal required for adaptation. As the regularizer acts only at the loss level, it requires no replay data, architectural changes, adapter redesign, or inference-time overhead, and can be applied directly to existing LoRA variants. Across all LoRA variants tested and across various backbones, our method improves the frontier between new learning and forgetting when the adaptation distribution differs substantially from the base models original training or alignment distributions, suggesting a broadly applicable route toward more reliable LLM updating.
ManipArena: Comprehensive Real-world Evaluation of Reasoning-Oriented Generalist Robot Manipulation
Mar 30, 2026Vision-Language-Action (VLA) models and world models have recently emerged as promising paradigms for general-purpose robotic intelligence, yet their progress is hindered by the lack of reliable evaluation protocols that reflect real-world deployment. Existing benchmarks are largely simulator-centric, which provide controllability but fail to capture the reality gap caused by perception noise, complex contact dynamics, hardware constraints, and system latency. Moreover, fragmented real-world evaluations across different robot platforms prevent fair and reproducible comparison. To address these challenges, we introduce ManipArena, a standardized evaluation framework designed to bridge simulation and real-world execution. ManipArena comprises 20 diverse tasks across 10,812 expert trajectories emphasizing reasoning-oriented manipulation tasks requiring semantic and spatial reasoning, supports multi-level generalization through controlled out-of-distribution settings, and incorporates long-horizon mobile manipulation beyond tabletop scenarios. The framework further provides rich sensory diagnostics, including low-level motor signals, and synchronized real-to-sim environments constructed via high-quality 3D scanning. Together, these features enable fair, realistic, and reproducible evaluation for both VLA and world model approaches, providing a scalable foundation for diagnosing and advancing embodied intelligence systems.
The Devil is in Attention Sharing: Improving Complex Non-rigid Image Editing Faithfulness via Attention Synergy
Dec 17, 2025Training-free image editing with large diffusion models has become practical, yet faithfully performing complex non-rigid edits (e.g., pose or shape changes) remains highly challenging. We identify a key underlying cause: attention collapse in existing attention sharing mechanisms, where either positional embeddings or semantic features dominate visual content retrieval, leading to over-editing or under-editing. To address this issue, we introduce SynPS, a method that Synergistically leverages Positional embeddings and Semantic information for faithful non-rigid image editing. We first propose an editing measurement that quantifies the required editing magnitude at each denoising step. Based on this measurement, we design an attention synergy pipeline that dynamically modulates the influence of positional embeddings, enabling SynPS to balance semantic modifications and fidelity preservation. By adaptively integrating positional and semantic cues, SynPS effectively avoids both over- and under-editing. Extensive experiments on public and newly curated benchmarks demonstrate the superior performance and faithfulness of our approach.
Face Transfer with Generative Adversarial Network
Oct 17, 2017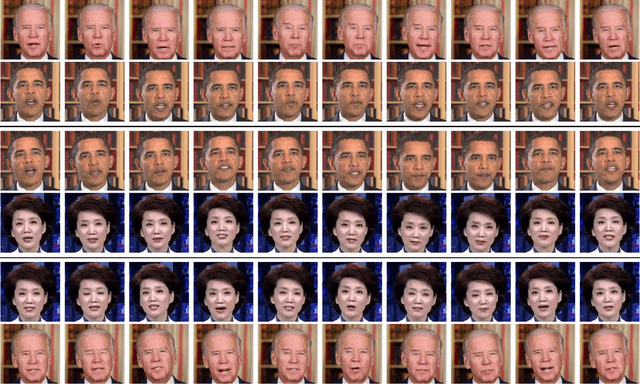



Face transfer animates the facial performances of the character in the target video by a source actor. Traditional methods are typically based on face modeling. We propose an end-to-end face transfer method based on Generative Adversarial Network. Specifically, we leverage CycleGAN to generate the face image of the target character with the corresponding head pose and facial expression of the source. In order to improve the quality of generated videos, we adopt PatchGAN and explore the effect of different receptive field sizes on generated images.